How to implement a web search application with the dtSearch Engine
Article: dts0220
This article will explain how to implement a web-Based search interface for a web site using the dtSearch Engine's .NET interface. Complete sample code for the interface described here is included with the dtSearch Engine in the examples\asp.net4 folder, in C# and VB.NET.
Another sample using ASP.NET Core/5/6 and the dtSearch Engine's .NET Standard API is included with the dtSearch Engine in the examples\NetStd\WebDemo, and is online here.
Indexing the web site
To index the web site, you can either use the dtSearch Desktop Indexer or you can use the .NET API. To build the index using the dtSearch Indexer,
1. Click Start > Programs > dtSearch Developer > dtSearch Indexer.
2. Click Create index (advanced)...
3. Enter a name for the index and check these two boxes under Indexing options: Cache document text in the index and Cache documents in the index. Caching text in the index makes display of hits-in-context in search results much faster.
4. Click OK, then click Yes when the indexer asks if you want to add documents to the index.
5. Click Add web... and add the starting URL for the web site(s) to be indexed.
For more information on building indexes of web sites, see How to index a web site with the dtSearch Spider and How to use dtSearch Web with dynamically-generated content.
To index a web site using the API, you would use the HttpDataSource class. The following is from the SpiderDemo sample included with the dtSearch Engine:
// Set up an IndexJob to build the index
indexJob = new IndexJobWeb;
indexJob.ActionCreate = true;
indexJob.ActionAdd = true;
indexJob.IndexPath = IndexPathEdit.Text;
indexJob.IndexingFlags =
IndexingFlags.dtsIndexCacheText |
IndexingFlags.dtsIndexCacheOriginalFile;
// Make data source to crawl the web sites
dataSource = new HttpDataSourceWeb;
foreach (WebSite ws in webSiteList)
{ dataSource.Add(ws);
}
// Start the Spider
dataSource.StartCrawlWeb;
// Attach the Spider's DataSource to the IndexJob
indexJob.DataSourceToIndex = dataSource;
// Start indexing.
indexJob.ExecuteInThreadWeb;
Searching the index
To search the index for a user-entered search request, set up a SearchJob with the search request and the index to be searched:
sj.Request = SearchRequest.Text;
sj.IndexesToSearch.Add("... index path goes here ....");
sj.ExecuteWeb;
// Get the results of the search
Results = sj.Results;
...
The search form for the search_cs sample provides additional options for search features such as fuzzy searching, boolean searching, etc.:
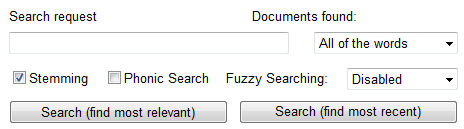
Transferring these form variables into the SearchJob is done in the DoSearchWeb method of the search_cs sample.
When the SearchJob is executed, the results are returned as a SearchResults object.
Displaying search results
The search_cs sample displays search results in a DataGrid control, showing the name and other properties of each document along with a brief snippet of text (the "synopsis") showing the first few hits in context:
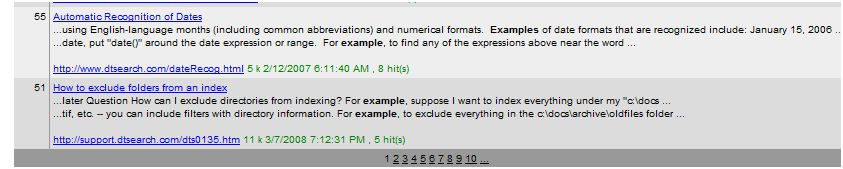
Because search results are displayed in pages, a DataSet containing document properties for the currently-selected page is generated to populate the DataGrid, in the ResultsToDataSet method in the sample. The current page of search results is converted to a range of items from search results (iFirst to iLim), and the data from these items is transferred into the DataSet:
int iFirst = iPage * ItemsPerPage;
int iLim = iFirst + ItemsPerPage;
if (iLim > results.Count)
iLim = results.Count;
GenerateSynopsis(results, iFirst, iLim);
for (int i = iFirst; i < iLim; ++i)
{
results.GetNthDoc(i);
SearchResultsItem item = results.CurrentItem;
DataRow row = dataTable.NewRowWeb;
row[0] = item.ScorePercent;
row[1] = item.HitCount;
row[2] = item.DisplayName;
...
Generating the synopsis to include in search results
The dtSearch Engine's SearchReportJob is used to generate the synopsis from SearchResults. SearchReportJob generates this text for each item in search results and stores it in the SearchResults object for convenient access. Because search results are displayed in pages, the synopsis is only generated for the range of items that going to appear on the current page.
rj.Flags =
ReportFlags.dtsReportLimitContiguousContext |
ReportFlags.dtsReportGetFromCache |
ReportFlags.dtsReportStoreInResults;
rj.SelectItems(iFirst, iLim);
// The itUnformattedHTML output format allows the
// search report to be generated in HTML,
// so characters such as < and > will be escaped
// properly, without allowing formatting in the original
// document to distort the appearance of search results.
rj.OutputFormat = OutputFormats.itUnformattedHTML;
rj.BeforeHit = "<b>";
rj.AfterHit = "</b>";
rj.WordsOfContextExact = 10;
rj.MaxContextBlocks = 2;
rj.ContextHeader = "...";
rj.ContextFooter = "...<br>";
rj.ExecuteWeb;
Highlighting hits
When the user clicks a link in search results, you can display the original document or you can display the document with hit highlighting added.
To display the original document, use the filename returned for each item found as the URL to include in search results for that item.
To display documents with hit highlighting, each link in search results has to point to a script that will convert the document to HTML and add hit highlight markings around the hits. The script will need to know which document was clicked and how to identify the hits in that document. With this information, the script can set up a dtSearch Engine FileConverter object to convert the retrieved item to HTML and add hit highlight markings around the hits.
In the search_cs sample, the link is created by this line of code:
row[3] = highlightAspx + "?" + results.UrlEncodeItemWeb;
This populates column [3] of each row in search results with a generated link. (In the DataGrid, column [3] of each row is the HighlightLink for that row.) The link generated has two parts: highlightAspx, which is the URL for highlighter.aspx in the sample, and results.UrlEncodeItemWeb, which contains the information dtSearch needs to highlight hits in an item search results, URL-encoded into a single string.
When the user clicks one of the links, highlighter.aspx will be invoked with the value generated by results.UrlEncodeItemWeb for that item in search results.
Highlighter.aspx uses that string value to reconstruct the original SearchResults item:
protected void Page_Load(object sender, System.EventArgs e) {
using (SearchResults res = new SearchResultsWeb) {
res.UrlDecodeItem(Request.ServerVariables.Get("QUERY_STRING"));
res.GetNthDoc(0);
Highlighter.aspx uses SearchResults.UrlDecodeItemWeb to reconstruct the original search results item Based on the url-encoded item in the link in search results. The next lines in Highlighter.aspx use the reconstructed SearchResults item to set up a FileConverter object with everything it needs to know about the original document and the hits to be highlighted. FileConverter's SetInputItem does this in one step by transferring all of the document properties from a SearchResults item into the FileConverter.
using (FileConverter fc = new FileConverter Web) {
fc.SetInputItem(res, 0);
FileConverter can generate output to a string or to a disk file, in HTML, RTF, or Unicode text. These lines specify HTML output, returned in a string, and limited to a maximum of 2 million bytes of output:
fc.OutputToString = true;
fc.OutputStringMaxSize = 2000000;
fc.OutputFormat = OutputFormats.itHTML;
You can use any HTML attributes you want to highlight hits. The following uses a yellow background:
fc.BeforeHit = "<span style=\"background-color: #FFFF00\">";
fc.AfterHit = "</span>";
Finally, call Execute to generate the HTML with the hit highlighting, and then use Response.Write to return it to the user:
fc.Execute Web;
Response.Write (fc.OutputString);
To summarize, to implement hit highlighting,
1. Use SearchResults.UrlEncodeItem to encode each item in search results in a string, and embed this string in links in search results.
2. When the user clicks one of the links, use SearchResults.UrlDecodeItem to reconstruct the original search results item from the data in the link.
3. Using the reconstructed SearchResults item, call FileConverter.SetInputItem to set up a FileConverter object with the document to be highlighted.
Additional features
The explanation above covers a basic implementation of hit highlighting. Two more complex aspects that are covered in the search_cs sample include highlighting hits in PDF files, and implementing hit navigation. For more information on these subjects, see Highlighting Hits in the dtSearch Engine API Reference.