File Type Rules
Menu option: Options > Preferences > File types
dtSearch recognizes most file formats automatically. If you are indexing only files such as word processor documents that dtSearch supports and can automatically recognize, you can disregard this section.
If you are indexing other types of files, dtSearch provides a way to specify how you want dtSearch to process the files. For each filter, you can specify a rule that tells dtSearch how you want the file to be handled. You can also use file type rules to override the default handling of some files. For example, you could make a rule to require *.html to be indexed as text, if you want to be able to search HTML tags.
Before using the file type information, dtSearch will try to detect the format itself. Therefore, no matter what file type specifications you enter, dtSearch will recognize formats such as Microsoft Word that it can detect automatically.
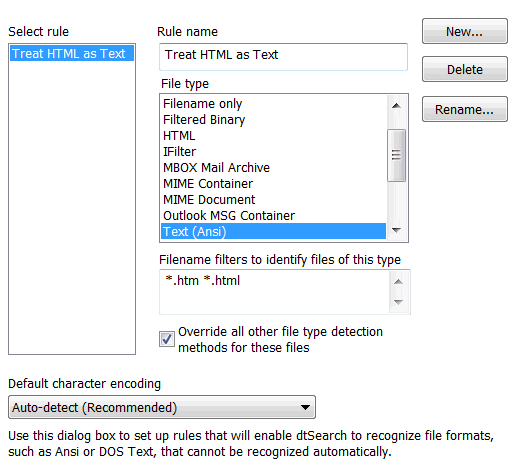
To set up a file type specification
1. Click New... to create a new item, and enter a name to identify it
2. Under File type, select the file format that the rule should select.
3. Under Filename filters, enter filters to identify files with this format.
4. Check the Override all other file type detection methods for these files box if you want dtSearch to always apply the rule, even if a document appears to have a different format.
File types
Several of the file types provide ways to change the way dtSearch indexes certain types of files, such as indexing only the name of a file, or indexing attachments separately from email messages.
"CSV as database"
"CSV as report"
CSV, or "comma-separated values", is a text format that can be used to store databases using commas to separate field values. Usually each row of a CSV file corresponds to one row of the database, with the field names in the first row. You can use these types to specify how dtSearch should treat CSV files. The "CSV as database" format treats each row of the CSV file as a separate document. The "CSV as report" format treats the whole CSV file as a report formatted into rows and columns, like a spreadsheet.
"Filename only"
Use the "Filename only" type to index only the name of files, ignoring the file contents.
"Filtered Binary"
See Filtering Options for information on how filtered documents are indexed.
"IFilter"
IFilters are components that enable various Microsoft search products, such as Microsoft Index Server, to extract text from documents. For example, when you install Microsoft OneNote, an IFilter is installed to enable searching of *.one files. To tell dtSearch to use installed IFilters to process some of your files, set up a rule in the file type table and under File type, select "IFilter".
"MIME Container"
"MIME Document"
A MIME file is an email file, usually with a .eml or .mht extension. MIME files can also be embedded in MBOX email archives, such as the email archives created by Thunderbird and Eudora. dtSearch can automatically detect MIME files and will index each email as a single document, combining the contents of all attachments at the end of the message body.
If you would rather have each attachment indexed as a separate document, you can create a rule specifying the files to index as "MIME Container" instead of "MIME Document".
For more information on this option, please see "How to index attachments separately from email messages"
"Outlook MSG Container"
A .msg file is an email created by Microsoft Outlook. When dtSearch indexes a PST message archive or indexes Outlook messages using the "Add Outlook" option in the dtSearch Indexer, each message is a single .msg file. dtSearch automatically detects .msg files and will index each email as a single document, combining the contents of all attachments at the end of the message body.
If you would rather have each attachment indexed as a separate document, you can create a rule specifying the files to index as "Outlook MSG Container".
For more information on this option, please see "How to index attachments separately from email messages"
Default character encoding
Plain text files, some older word processsor files, and HTML files written in languages other than English use a character encoding to specify the meaning of characters in the range from 128 to 255. For example, a Russian document might have the CP1251 encoding, which uses these characters for Cyrillic letters. By default, dtSearch will try to automatically detect the encoding of these types of documents based on an analysis of the contents. If you find that the auto-detection is not working for your documents, you can specify the encoding that dtSearch should assume for documents that do not specify one. To do this, select an encoding from the drop-down list under Default character encoding.